NPBにおけるピタゴラス勝率と実際の勝率
スポーツアナリティクス Advent Calendar 2020の14日目の記事です。
はじめに
みなさんピタゴラス勝率をご存知でしょうか。ざっくりいうと得点と失点と勝率の関係を表したもので、以下ような単純な式で表されます。
このピタゴラス勝率について、Essence of Baseballさんのサイトを見てると以下の記述が目につきました。
また、 ピタゴラス勝率をチームの戦力と考え、実際の勝率との差は監督の能力を表すとする分析も見られるが、このような使用法は適切でないとされている。ピタゴラス勝率自体の高低にも監督の影響は及んでいるはずであるし、監督が同じでもピタゴラス勝率と実際の勝率との乖離には継続性が見られないからである。
このなかの「監督が同じでもピタゴラス勝率と実際の勝率との乖離には継続性が見られない」という箇所について気になったのでそれらしきデータがどこかにないのかと探してみたのですが、特に見つかりませんでした。
そこで本記事では、プロ野球におけるピタゴラス勝率と実際の勝率の関係について可視化しながら、チームや監督によってピタゴラス勝率と実際の勝率との乖離があるのかを調べていこうと思います。
(データは楽天が参戦して現在の12球団になった2005シーズン以降のものを使用しています。)
ピタゴラス勝率と実際の勝率の関係
まずはピタゴラス勝率と実際の勝率がどのような関係になっているかを見ていきます。下の図は2005シーズン以降における12球団のピタゴラス勝率と実際の勝率の散布図です。青線はピタゴラス勝率=実際の勝率となっており、この線より上だとピタゴラス勝率より実際の勝率が高く、下だと低いことを表してます。
いずれの点も青線に近く、ピタゴラス勝率で実際の勝率をかなり精度よく近似できていることがわかります。
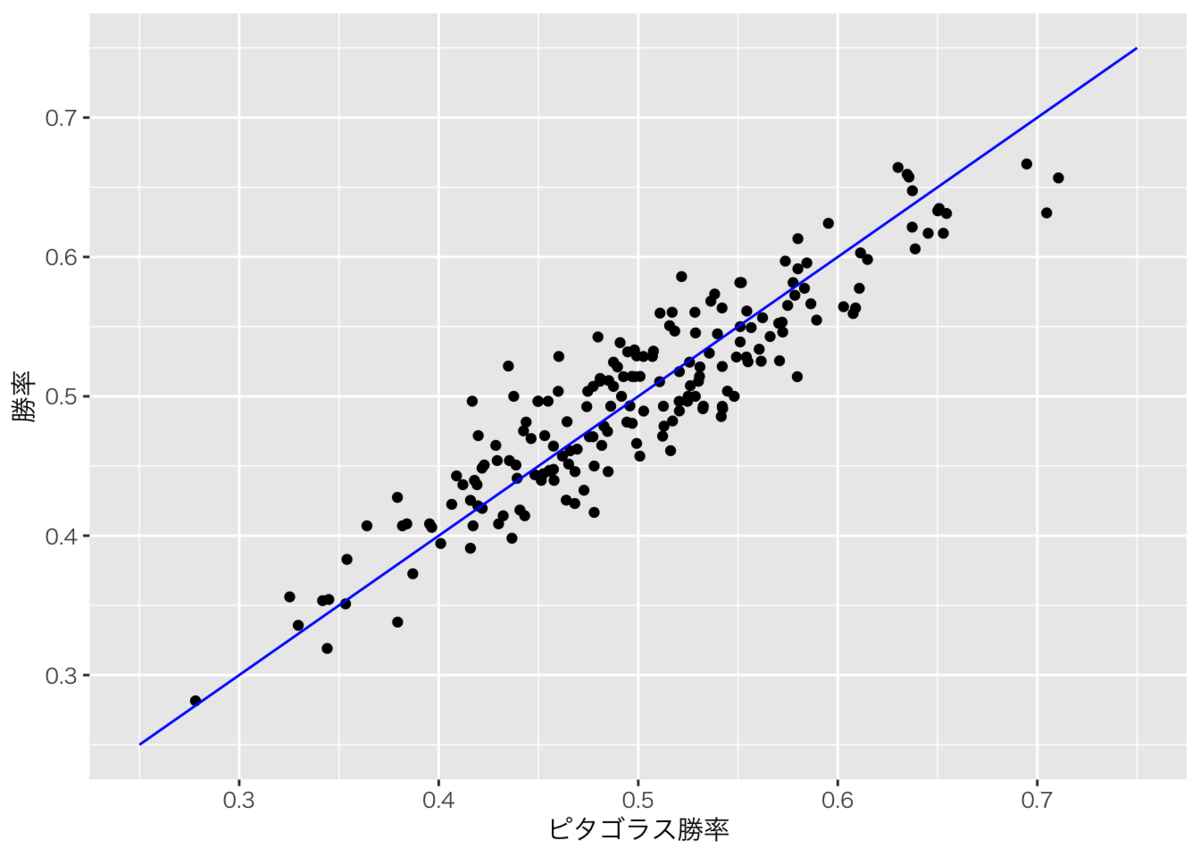
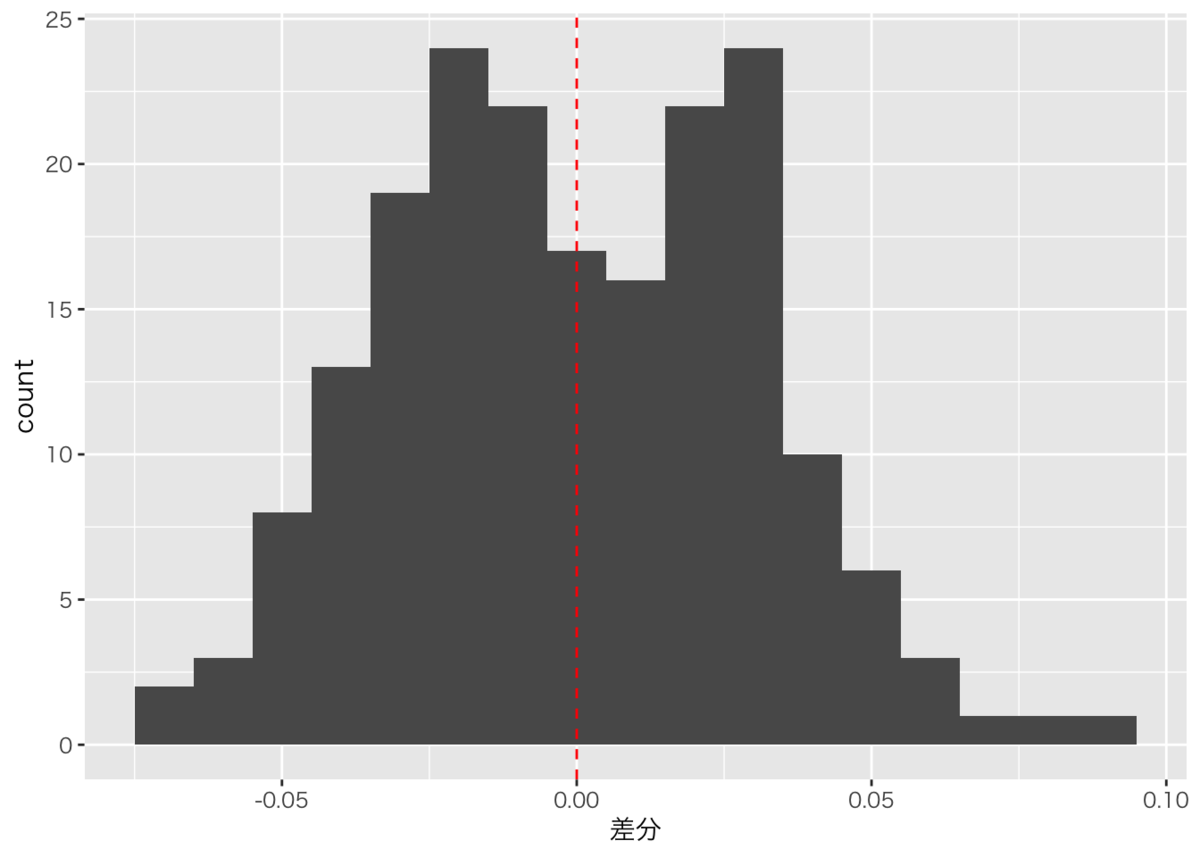
上のグラフだとピタゴラス勝率と実際の勝率の乖離がどのくらいの大きさなのか少しわかりにくいので、ピタゴラス勝率と実際の勝率の差をヒストグラムで表してみます。大体±0.05(5%)に収まっているようです。
(今回の例に当てはめていいかは微妙ですが、偶然の要素で0.05程度はブレてもおかしくないので妥当な誤差だと思います。詳しくは去年自分がJapan.Rで発表したスライドをご覧ください)
20191207_japanr_LT - Google スライド
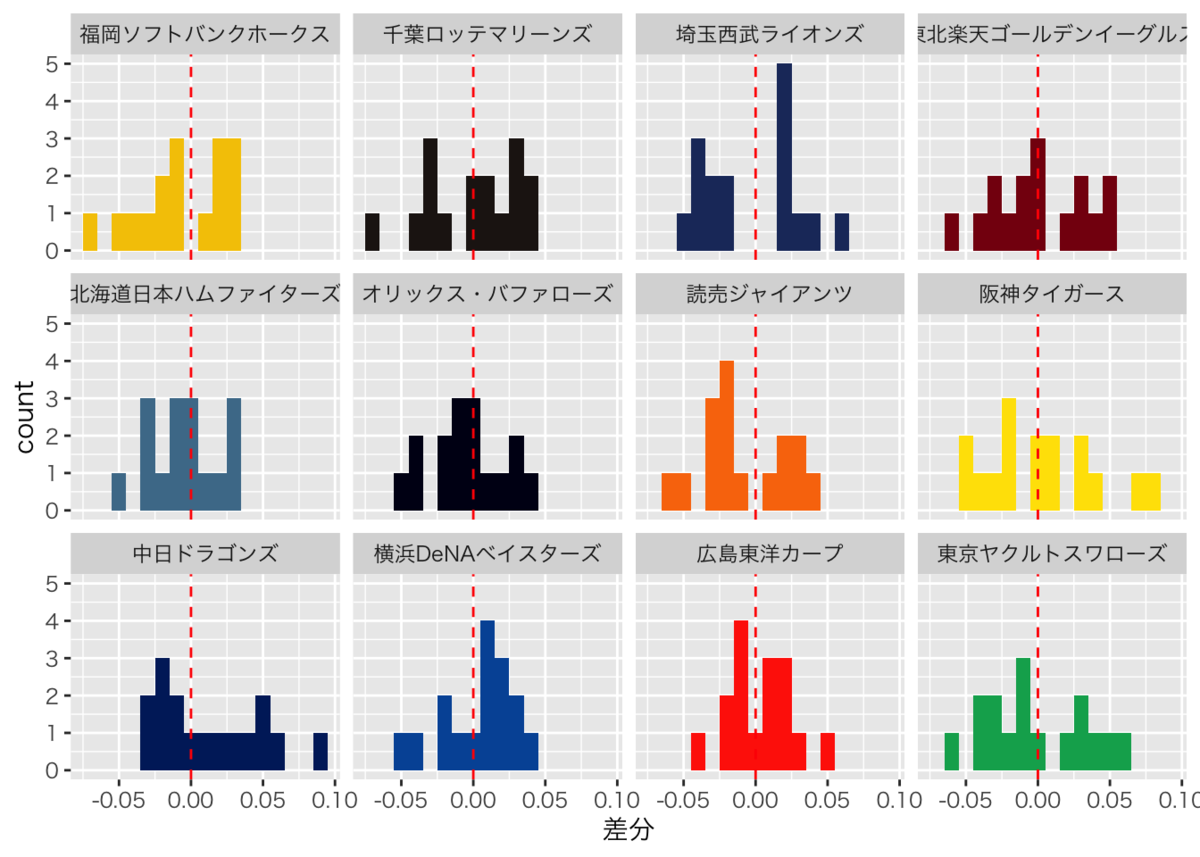
チームごとの関係
次に先ほどのグラフをチームごとに分けて描いてみます。特定のチームがピタゴラス勝率と比較して実際の勝率が高かったり低かったりみたいな傾向はないように見えます。

ヒストグラムで見ても同様です。強いて言えば中日がプラス側に偏っている気がしますが、12球団もあれば1球団くらいは偏っていても確率的におかしくないので判断が難しいです。
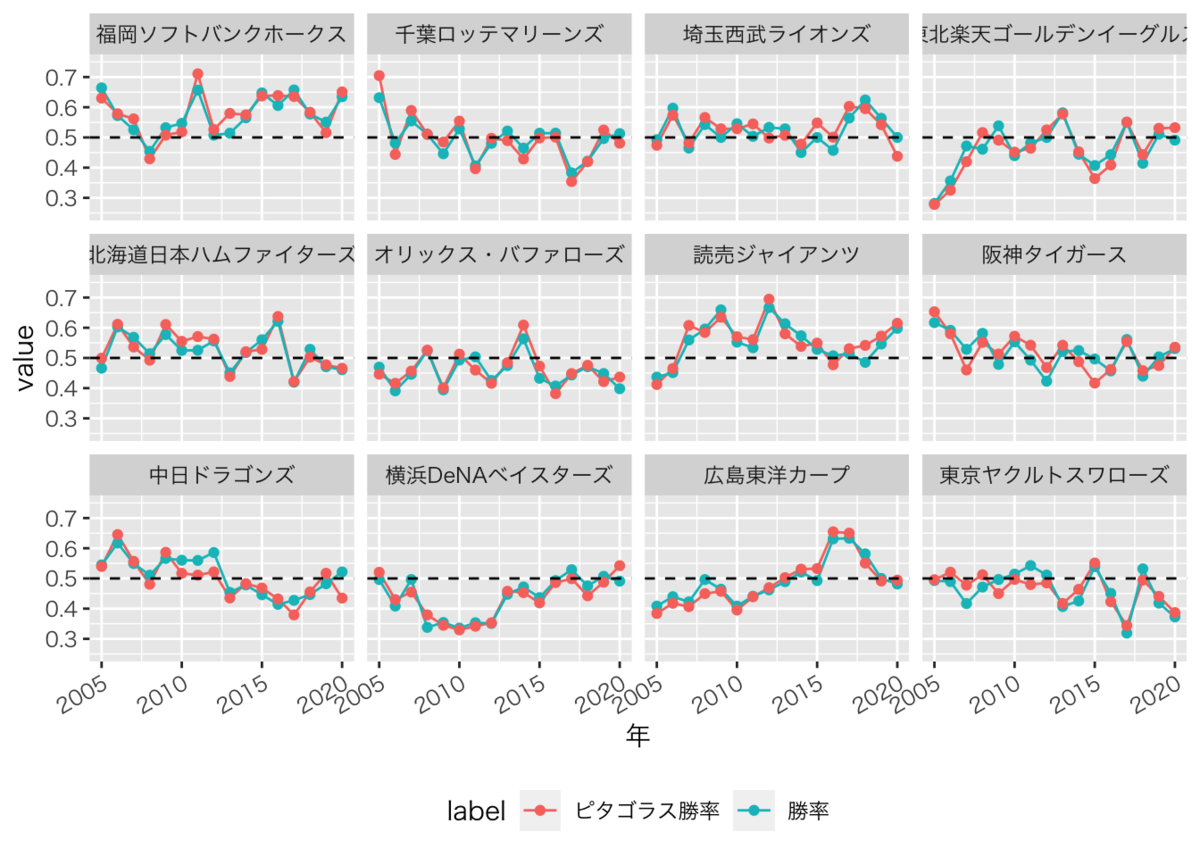
時系列で比較
ではチームごとのピタゴラス勝率と実際の勝率の関係を時系列で見てみましょう。赤がピタゴラス勝率で緑が実際の勝率となっています。中日に注目してみると、2010年〜2012年の3年連続で実際の勝率がピタゴラス勝率を0.05程度上回っています。ただ、2010、2011年は落合監督ですが、2012年は高木監督に変わっているのに加え、両監督の他のシーズンは継続的に上回っているわけではなさそうです。(落合監督は2004~2011年、高木監督(第2次)は2012~2013年)
また、2017年は0.048、2020年は0.087とこちらも大きく上回ってますが、2017年は森監督、2020年は与田監督と監督が異なっています。さらに両監督の他のシーズンはむしろ下回っていたりと、特定の監督が安定して実際の勝率がピタゴラス勝率を上回るという傾向はなさそうです。

まとめ
以上の結果から、Essence of Baseballさんのピタゴラス勝率の説明にあるように、ピタゴラス勝率と実際の勝率との乖離には継続性が見られないことがデータから見て取れました。やっぱりある程度の期間を見るのは大事ですね!
おまけ
今回分析に使ったデータを使って、対象期間内のピタゴラス勝率のベスト/ワースト3、ピタゴラス勝率と実際の勝率の差ベスト/ワースト3も見てみようと思います。(チーム名はフルで書くとテーブルの見た目が悪くなるので省略)
ピタゴラス勝率ベスト3
1位は17.5ゲーム差をつけてぶっちぎりで優勝した2011年のソフトバンクホークスです。ピタゴラス勝率的にはもう少し勝ってもおかしくなかったのは恐ろしいですね...
| チーム | 年 | 試合数 | 勝ち | 負け | 引き分け | 得点 | 失点 | 実際の勝率 | ピタゴラス勝率 | 実際の勝率 - ピタゴラス勝率 |
|---|---|---|---|---|---|---|---|---|---|---|
| SB | 2011 | 144 | 88 | 46 | 10 | 550 | 351 | 0.657 | 0.711 | -0.054 |
| ロッテ | 2005 | 136 | 84 | 49 | 3 | 740 | 479 | 0.632 | 0.705 | -0.073 |
| 巨人 | 2012 | 144 | 86 | 43 | 15 | 534 | 354 | 0.667 | 0.695 | -0.028 |
ピタゴラス勝率ワースト3
球団創設時の楽天が1, 2位という結果です。どちらかというと3位だけでなく4, 6, 7位を占めている2009~2012年の横浜が際立っています...
| チーム | 年 | 試合数 | 勝ち | 負け | 引き分け | 得点 | 失点 | 実際の勝率 | ピタゴラス勝率 | 実際の勝率 - ピタゴラス勝率 |
|---|---|---|---|---|---|---|---|---|---|---|
| 楽天 | 2005 | 136 | 38 | 97 | 1 | 504 | 812 | 0.282 | 0.278 | 0.004 |
| 楽天 | 2006 | 136 | 47 | 85 | 4 | 452 | 651 | 0.356 | 0.325 | 0.031 |
| 横浜 | 2010 | 144 | 48 | 95 | 1 | 521 | 743 | 0.336 | 0.330 | 0.006 |
ピタゴラス勝率と実際の勝率の差ベスト3
1位は今シーズンの中日でした。2位の阪神は名将ポイントという指標で盛り上がったみたいです。
| チーム | 年 | 試合数 | 勝ち | 負け | 引き分け | 得点 | 失点 | 実際の勝率 | ピタゴラス勝率 | 実際の勝率 - ピタゴラス勝率 |
|---|---|---|---|---|---|---|---|---|---|---|
| 中日 | 2020 | 120 | 60 | 55 | 5 | 429 | 489 | 0.522 | 0.435 | 0.087 |
| 阪神 | 2015 | 143 | 70 | 71 | 2 | 465 | 550 | 0.497 | 0.417 | 0.080 |
| 阪神 | 2010 | 144 | 74 | 66 | 4 | 518 | 561 | 0.529 | 0.460 | 0.069 |
ピタゴラス勝率と実際の勝率の差ワースト3
1位は2005年のロッテでした。この年のロッテはピタゴラス勝率的には圧倒的に優勝しておかしくなかったのですが、ソフトバンクに敗れ2位となっています。しかしクライマックスシリーズをソフトバンクとの接戦の末に勝ち上がり、日本シリーズは阪神に圧勝して見事日本一に輝いています。
2位は2013年のソフトバンクです。ピタゴラス勝率的には楽天と優勝争いしてもおかしくありませんでしたが、最終的に4位と2010年代唯一のBクラスという結果に終わっています。
| チーム | 年 | 試合数 | 勝ち | 負け | 引き分け | 得点 | 失点 | 実際の勝率 | ピタゴラス勝率 | 実際の勝率 - ピタゴラス勝率 |
|---|---|---|---|---|---|---|---|---|---|---|
| ロッテ | 2005 | 136 | 84 | 49 | 3 | 740 | 479 | 0.632 | 0.705 | -0.073 |
| SB | 2013 | 144 | 73 | 69 | 2 | 660 | 562 | 0.514 | 0.580 | -0.066 |
| ヤクルト | 2010 | 144 | 60 | 84 | 0 | 596 | 623 | 0.417 | 0.478 | -0.061 |
全チーム同じ強さでシミュレーションしてみた(サッカーJ1編)
「スポーツアナリティクス Advent Calendar 2019」*1 の15日目の記事です.
そして, 12/7に行われたJapan.R *2 でのLT発表 *3 をサッカーのJ1でも検証してみた内容になります.
はじめに
サッカーJ1のチームが全て同じ実力の場合, リーグ戦の結果はどうなるでしょうか?
1チームあたり34試合行うので, 全チーム17勝17敗? それとも引き分けも考慮して13勝13敗8分くらい?
もちろんそういった結果になる可能性もありますが, 実際には運がいいチームと悪いチームで差が出てしまいます. その差がどの程度になるのかをシミュレーションで求め, 実際のJ1の結果と比較としたのが今回の記事となります.
J1のルール
まず, シミュレーションを行う前にJ1のルール *4 について整理します.
今回関係がある箇所をまとめると,
1. 全18チームによるホーム&アウェイ方式による2回戦総当たりリーグ戦(同じチームと2試合する)
2. リーグ戦終了時点, 勝点合計の多いチームを上位とし, 順位を決定(勝利: 3点, 引き分け: 1点, 敗戦: 0点)
の2点になります. プロ野球の場合は勝率で順位を決めるのですが, J1の場合は勝点で順位を決めています. サッカーは引き分けになる確率も高いので, 引き分けを無視することはできなさそうです.
今回は実際のJ1の結果から引き分けになる確率を23%としてシミュレーションを行いました. (勝ち: 38.5%, 引き分け: 23%, 負け: 38.5%)
10000シーズン分シミュレーション
ルールがわかったので早速シミュレーションしてみます.
全チームの勝点の分布
18チーム×10000シーズン分の勝点の分布は以下のようになりました.
47あたりの勝点になることが最も多く, そこから離れるほど少なくなっていますが, 60を超えたり25を下回ったりすることも割とあるようです.

優勝チームの勝点の分布
次に優勝チーム(各シーズンで勝点が一番大きいチーム)の勝点分布です.
61前後が最も多いですが, 70を超えたり55を下回ったりすることもある様子.

最下位チームの勝点の分布
同様に最下位チーム(各シーズンで勝点が一番小さいチーム)の勝点分布です.
優勝チームの線対称な分布となっており, 33前後が最も多いですが, 40を超えたり25を下回ったりすることもあるようです.

実際のJ1の結果と比較
では実際のJ1における結果はどのようになっているのか, シミュレーション結果と比較していきましょう. 今回はJ1が18チームになった2005年以降の15シーズン分の結果を比較に用いています.
全チームの勝点分布
70以上や25以下の勝点もけっこうあることがわかります. シミュレーション結果と比べて, 広がりが大きい分布となっているようです.

優勝チームの勝点の分布
15シーズン分しかないですが, 実際の優勝チームの勝点は70程度となることが多いようです. とはいえ, 60で優勝している年 *5 もありました.
シミュレーション結果と比較すると, 実際の結果の方が大きい勝点となっているようです.

最下位チームの勝点の分布
実際の最下位チームの勝点は20前後と優勝チーム以上にシミュレーションの分布と異なっているようです...

まとめ
全チームの強さが同じと仮定してリーグ戦のシミュレーションを行ってみた結果, 優勝チームの勝点は61程度, 最下位チームの勝点は33程度になることがわかりました.
実際のJ1における勝点の分布はシミュレーション結果と異なることから, 当然ですがJ1は完全な運ゲー(実力差なし)という訳ではさなそうです.
KDD2019: Actions Speak Louder than Goals: Valuing Player Actions in Soccer まとめ
今月の頭にアラスカのアンカレッジで開催されたKDD2019に参加してきました。 KDDはデータマイニングに関する国際会議で、この分野では最難関と位置づけられています。 アルゴリズムや手法を対象とするResearch Trackと実問題への応用を対象とするApplied Data Science Trackに分かれており、今年はApplied Data Science Trackのベストペーパーをサッカーにおけるアクションの評価に関する論文が獲得しました。 今回は自分の理解を深める目的でそちらの論文をまとめようと思います。
- KDD2019 | Actions Speak Louder Than Goals: Valuing Player Actions in Soccer
- GitHub - ML-KULeuven/socceraction: Convert existing soccer event stream data to SPADL and value player actions
- KDDの発表Slide
はじめに
サッカーは連続的にアクションが行われるうえに、あまり点が入らず多くのアクションがスコアに直接影響を及しません。そのような難しさから、個々のアクションを評価するということは行われていませんでした。そこで本論文では、個々のアクションを評価するため、次の5つについて書かれています。
- 試合中のアクションを説明するデータ形式(SPADL)
- アクションを評価するフレームワーク(VAEP)
- 機械学習による得点/失点確率の予測
- 実際の試合結果を用いたユースケースの紹介
- Pythonパッケージの公開
SPADL: A LANGUAGE FOR DESCRIBING PLAYER ACTIONS
本論文ではドメイン知識と専門家からのフィードバックを元にSPADL(Soccer Player Action Description Language)というフォーマットを定義しています。
SPADLでは、試合中のボールに絡んだ選手のアクションを時系列順に[ ]とし、それぞれのアクションを次の情報で説明しています。
- StartTime: アクションの開始時間
- EndTime: アクションの終了時間
- StartLoc: アクションの開始位置
- EndLoc: アクションの終了位置
- Player: アクションを行なった選手
- Team: 選手の所属チーム
- ActionType: アクションの種類(パス、シュート、ドリブルなど)
- BodyPart: 体のどの箇所でアクションを行なったか
- Result: アクションの成否
つまり、いつどこで誰がどんなアクションをしたか(とその成否)を説明するフォーマットとなっています。 ActionTypeはパス、クロス、ドリブルなどの21種類が定義されています。
また、Opta/Wyscout/StatsBombのデータならこちらのPythonパッケージでSPADLに変換できるようです。
VAEP: A FRAMEWORK FOR VALUING PLAYER ACTIONS
次に選手のアクションを評価するフレームワークについてです。本論文ではVAEP: Valuing Actions by Estimating Probabilitiesというフレームワークを提案しています。
サッカーにおけるアクションの目的は、自分たちがゴールする確率を増やす(オフェンス)と相手がゴールする確率を減らす(デフェンス)の2つに分けられると考えられます。VAEPでは、アクションがどのくらいチームの得点確率を増やしたか及び失点確率を減らしたかでそのアクションを評価しています。
試合開始から回のアクションが行われた時点の状況を
[
]、
ボールを持っているチームが10アクション以内に得点する確率、失点する確率をそれぞれ
、
とします。
その時、アクションがチームの得点確率に与えた影響は
、失点に与えた影響は
と考えられます。
それらから、得点と失点に与えた影響度をアクション
の価値(VAEP Value)と定義しています。(マイナスなのは失点確率を減らすのがデフェンスの目的のため)
ESTIMATING SCORING AND CONCEDING PROBABILITIES
VAEPではと
から各アクションの価値を求めています。となれば如何にしてそれらを求めるかが重要となります。
本論文では機械学習を用いて以下の特徴量とラベルから予測しています。
特徴量
- SPADLをそのまま利用した特徴量
- Action Type, Result, BodyPart, Start&End Location, StartTime
- SPADLから求めた特徴量
- ゴールまでの距離と角度、1アクション間の位置変化(StartLoc - EndLoc?)、ボールを保持しているチームが変わったかのフラグ、アクションとアクション間の時間と位置変化
- 試合経過に関する特徴量
- 各チームのスコアとその差分
- SPADLをそのまま利用した特徴量
ラベル
- 10アクション以内にゴールが入った場合は1、それ以外は0
アルゴリズムはCatBoost、ロジスティック回帰、ランダムフォレスト、XGBoostを検証しており、予測した確率を評価するのにBrier Scoreを、不均衡なデータに対してのモデルの性能を評価するのにROC AUCを用いています。(両指標において最もよかったCatBoostを採用)
Experiments
ヨーロッパのトップリーグ(イングランド、スペイン、ドイツなど)の2012/2013シーズンから2017/2018シーズンの全11565試合のデータを使って実験を行なっています。
結果のグラフや表はたくさんあってまとめきれないので、論文やスライドをご覧下さい。 本手法ではActionType毎のレーティングを求めることも可能なので、選手がどういったタイプなのかもわかって面白いです。
また、論文中のDiscussion of remaining challengesでも述べられているのですが、VAEPのフレームワークだとボールに絡んだアクションしか評価されません。そのため、敵を引きつける動きだったり相手のパスコースを消すといった動きは評価されていない点は考慮して結果を見る必要があるとは思います。
おわりに
こちらのツイートにあるように、Sport Analyst Meetup#4で本論文についてのLTをやる予定です。面白い発表になるよう頑張ります。
個人的には、本論文で提案されているVAEPはさることながら、目的に合ったデータ形式を定義するところから実際のデータでの検証及び考察まで、データサイエンスのプロセスをしっかりと行なっている点がとても勉強になりました。
余談ですが、タイトルのActions Speak Louder than Goalsは、Actions Speak Louder Than Words:「行動は言葉より雄弁だ」という諺が元となっているようです。かっこいいですね! Actions speak louder than words.の意味・使い方 - 英和辞典 WEBLIO辞書
useR!2019@Toulouse参加(+ポスター発表)記録
表題のとおり、フランスのトゥールーズで開催されたuseR!2019に参加(+ポスター発表)してきました。 自分がきいた内容の一部とその感想を簡単にまとめておこうと思います。
useR!とは
R言語のユーザーカンファレンスです。 今年は7月9日から12日までの4日間の開催で、1日目はチュートリアル、2~4日目はキーノートや6パラレルで行われるトークやLTがありました。 また、2日目の夜にはディナーパーティー、3日目の夜にはポスター発表がありました。
殆どの発表はこちらで資料が公開されており、 youtubeに動画もあがっています。
また、twitterのハッシュタグ#user2019で参加者のツイートを見ることができますし、ShinyでつくられたこちらのDashboardも面白かったです。


Tutorial
初日はTutorialで、午前は可視化、午後はSNSデータ分析のものに参加しました。
Visualising High-Dimensional Data
隣の人とこのグラフから何がわかるか/より良くするにはどうしたらよいか等をディスカッションしながら進めていく形式。 大学の講義みたいで面白かったです。
Watch me: introduction to social media analytics
{rtweet}を使ってtwitterデータを取得し、Word Cloudで可視化したりしました。移動の疲れと時差ボケで後半キツかったです...
Keynote
R for better science in less time
スターウォーズに例えたRとコミュニティの話。
Shiny's Holy Grail: Interactivity with reproducibility
- 資料: こちらからzipファイルをダウンロード
InteractivityのあるShinyでreproducibility(再現性)をいかにして実現するかという話。 試作libraryの{shinymeta}も紹介された。
'AI for Good' in the R and Python ecosystems
Hard question to researchers: Are you here to solve a problem? or to illustrate your method?
Talks
Enhancements to data tidying
- 資料: なし
Hadleyによる{tidyr}の新function(pivot_longer/pivot_wider)の紹介 こちらのtweetにもあるように、Tokyo.Rの湯谷さんの資料を読んでから動画を見るとわかりやすいと思います。
n() cool #dplyr things
- 資料: 資料
{dplyr}のgroup_hoge()の紹介。
Flexible futures for fable functionality
- 資料: 資料
tidyver"ts"ファミリーにおけるforecastのlibraryである{fable}の紹介。prophetと連携もできるようになったらしく、個人的に使ってみたいと思う。
A feast of time series tools
- 資料: 資料
同じくtidyver"ts"ファミリーである{feast}の紹介。時系列データの特徴量を可視化する際に便利そう。
Experiences from dealing with missing values in sensor time series data
- 資料: 資料
時系列データにおける欠損値補完libraryの{imputeTS}の紹介。このlibraryは何回か使ったことがあるのだが、色々と機能が増えていたので試してみたい。
LT
Spatial Optimisation with OSRM and R
- 資料: 資料
トゥールーズの地図について、 RでOpenStreetMap-Based Routing Serviceを扱える{osmr}を用いてホテルからランニングで行ける場所をヒートマップで可視化。
Anomaly detection in trivago
- 資料: 資料
trivagoの異常検知事例。
Using R and the Tidyverse to Play Fantasy Baseball
- 資料: 資料
野球ネタ。
Poster
3日目の夕方はPoster Sessionがありました。
英語でのディスカッションは大変でしたが、Rユーザーから色々なフィードバックをもらうことができよかったです。

さいごに
来年はアメリカのセントルイスで開催されるみたいです。来年も参加できるように頑張りたいと思います。

おまけ: トゥールーズについて
ここからはuseR!関係なく、開催地であるトゥールーズを観光した写真をペタペタ貼っていきたいと思います。
トゥールーズはフランスの南西部にあり、位置は以下の感じです。(ちなみに、ミュンヘン乗り継ぎでした)
また、エアバスの本社もありヨーロッパの航空宇宙産業の中心地となっています。そのためか宇宙のテーマパークCite de l'espaceもあり、useR!のDinnerもこちらで行われました。

なぜかカンファレンス会場の隣に日本庭園がありました。


あまり観光する時間がなかったので、最終日は少し早めにホテルを出て、1時間くらい遠回りをして観光名所を回りながらカンファレンス会場に向かいました。




ちょうど自転車レースのツール・ド・フランスの開催期間中で、ホテルにはこのような掲示物もありました。(useR!2019の約1週間後にトゥールーズもコースの一部となったようです)

今度はカンファレンス抜きで行って、ゆっくり観光したいなと思うくらいにいい都市でした!